HisDoc
Historical Document Analysis, Recognition and Retrieval
The HisDoc project is a scientific research project dedicated to textual heritage, it aims at the development of a complete processing chain for analysis, recognition, indexation and retrieval of historical documents. The project was launched in 2009 and completed by the end of June 2013.
The follow-up project HisDoc 2.0 started in January 2014 and sucessfully finished in December 2016. It was directly succeeded by HisDoc III in January 2017.
Project Partners
University of Fribourg
Document Image Analysis
University of Bern
Handwriting Recognition
University of Neuchatel
Information Retrieval
Swiss National Science Foundation
Project Funding
HisDoc - The Idea
HisDoc is a pioneering research project in the field of automated historical manuscript processing. The fundamental research has demonstrated promising possibilities as well as limitations of the current state-of-the art and has laid a strong basis for future investigations. The HisDoc project is organized in three complementary modules:
- layout analysis,
- handwriting recognition, and
- information retrieval.
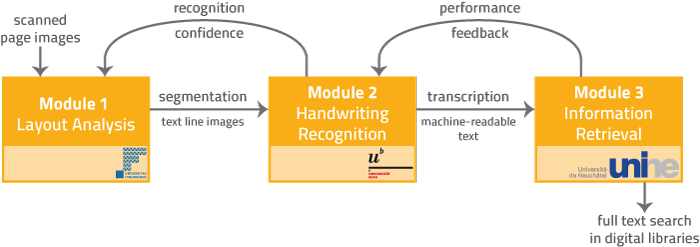
Each of the three HisDoc modules is treated in an individual doctoral thesis. Scientific achievements have been disseminated so far in 2 journal articles and 27 peer-reviewed conference papers. Publications
Module 1 - Layout Analysis
![]() The first module has produced a generic tool for segmenting historical documents into regions labeled as text blocks, illustrations, ornaments, noise and background. Particular attention is paid to text blocks, which are further analyzed and split into text lines. Two complementary approaches have been studied: the first uses a pyramidal approach hierarchically classifying pixels using textural features combined with morphological filters; the second approach clusters points of interests describing parts of characters to text lines. More...
The first module has produced a generic tool for segmenting historical documents into regions labeled as text blocks, illustrations, ornaments, noise and background. Particular attention is paid to text blocks, which are further analyzed and split into text lines. Two complementary approaches have been studied: the first uses a pyramidal approach hierarchically classifying pixels using textural features combined with morphological filters; the second approach clusters points of interests describing parts of characters to text lines. More...
Module 2 - Handwriting Recognition
![]() The second module’s goal is to provide fully automatic transcriptions of text line images. Two systems were developed for this task: first, a generative one based on hidden Markov models and, secondly, a discriminative one based on recurrent neural networks. They have proven both a high robustness and a high flexibility. In this context, robustness means that they achieve high recognition accuracy, and flexibility means that they can be adapted without great effort to different scripts and languages. More...
The second module’s goal is to provide fully automatic transcriptions of text line images. Two systems were developed for this task: first, a generative one based on hidden Markov models and, secondly, a discriminative one based on recurrent neural networks. They have proven both a high robustness and a high flexibility. In this context, robustness means that they achieve high recognition accuracy, and flexibility means that they can be adapted without great effort to different scripts and languages. More...
Module 3 - Information Retrieval
![]() The goal of the third module was to implement a search engine for noisy transcriptions provided by automatic handwriting recognition. To partially compensate for errors in the transcription, two strategies have been successfully pursued. First, augmenting the text representation with recognition alternatives and, second, extending the search query with typical word confusion candidates. More...
The goal of the third module was to implement a search engine for noisy transcriptions provided by automatic handwriting recognition. To partially compensate for errors in the transcription, two strategies have been successfully pursued. First, augmenting the text representation with recognition alternatives and, second, extending the search query with typical word confusion candidates. More...
Participants
![]() Prof. Dr. Rolf Ingold
Prof. Dr. Rolf Ingold
Micheal Baechler, PhD Student
DIVA Group
![]() Prof. Dr. Horst Bunke
Prof. Dr. Horst Bunke
Dr. Andreas Fischer
Institute of Computer Science & Applied Mathematics
![]() Prof. Dr. Jacques Savoy
Prof. Dr. Jacques Savoy
Nada Naji, PhD Student
Computer Science Department (IIUN)