HisDoc 2.0
Towards Computer-Assisted Palaeography
HisDoc 2.0 is a follow-up project of the successful HisDoc Project. It has been granted by the Swiss National Science Foundation, and started in January 2014.
The follow up project HisDoc III started in 2017.
Recent News
-
Thu, 26 April 2018
HisDoc III represented at DAS 2018 in Vienna
-
Mon, 23 January 2017
HIP'17 Workshop at ICDAR 2017
Project Conductor
University of Fribourg
Document Image Analysis
Swiss National Science Foundation
Project Funding
The new HisDoc 2.0 project will be of smaller scale and concentrated at University of Fribourg.
HisDoc 2.0 - The Idea
In HisDoc 2.0 we will investigate the yet missing ingredients for automatic large-scale analysis of historical documents, and how to make the results useful for historians. It will build upon the foundations laid in the HisDoc project and continue research on textual heritage preservation in a novel direction.
HisDoc 2.0 will take the approach a step further: it will be dedicated to palaeographical studies and incorporate semantic domain knowledge automatically extracted from existing document databases into Document Image Analysis (DIA) methods in order to facilitate large-scale processing.
Holistic DIA Approach
The innovations of HisDoc 2.0 are two-fold. First, we will address documents with complex layouts and several scribes, which have been circuited by the research community so far. Existing approaches presume laboratory conditions (e.g. high-quality binarization, or pre-segmented texts regions) and focus on sub-tasks, treating interrelated tasks independently.
In real-world applications, mutual dependencies exist, e.g. reliable script analysis depends on the exact localization of text regions on a page, which in presence of various kinds of scripts or personal writing styles then again depends on discriminating scripts. We will exploit mutual dependencies and analyze, develop, and integrate methods for text localization, script discrimination, and scribe identification into one holistic approach in order to obtain a flexible, robust, and generic approach for historical manuscript analysis in presence of complex layouts.
Semantic Domain Knowledge
Our second innovation will be to incorporate additional domain knowledge into DIA algorithms. We will investigate how existing image analysis methods and new approaches can be improved by integrating domain knowledge derived from semantic document descriptions which will be extracted from public sources like e-codices and manuscripta mediaevalia. Furthermore, we will study how results of DIA can be used for generating meaningful semantic information (i.e., human-readable and useful for scholars) in order to enhance and possibly verify existing descriptions.
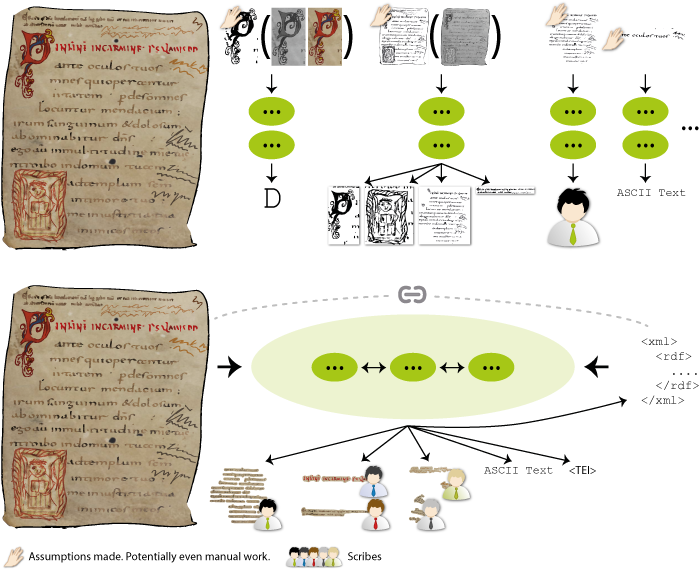
In HisDoc 2.0, we will formulate several novel research perspectives, propose new contributions for document image analysis, and bring research one step further towards holistic systems rather than sub-task solving in restricted environments. This integrated approach opens new doors towards self-improving DIA methods and beyond.
Team
![]() Angelika Garz, PhD Student
Angelika Garz, PhD Student
Marcel Würsch, PhD Student
Dr. Fotini Simistira
Dr. Manuel Bouillon
Dr. Andreas Fischer
Dr. Marcus Liwicki
Prof. Dr. Rolf Ingold