DIVADIA
DivaDia is a project related to HisDoc 2.0. It is a Document Image Analysis (DIA) framework which is part of an ongoing research project at DIVA (Document, Image, and Video Analysis) research group.
It aims at the development of a tool for semi-automatic analysis, in particular layout analysis of historical documents.
DivaDia assists users in labeling parts of documents, such as text, images, and initials by learning from their input, i.e., based on a few document images manually annotated by a user, the system learns a model of the document(s) which empowers it to predict the labeling of an unseen page.
It suggests a solution to the user, who validates it. Validation in this context refers to accepting or modifying the predict solution.
The validation data is then used to improve the prediction model in order to generate better solutions for further pages.
System Overview
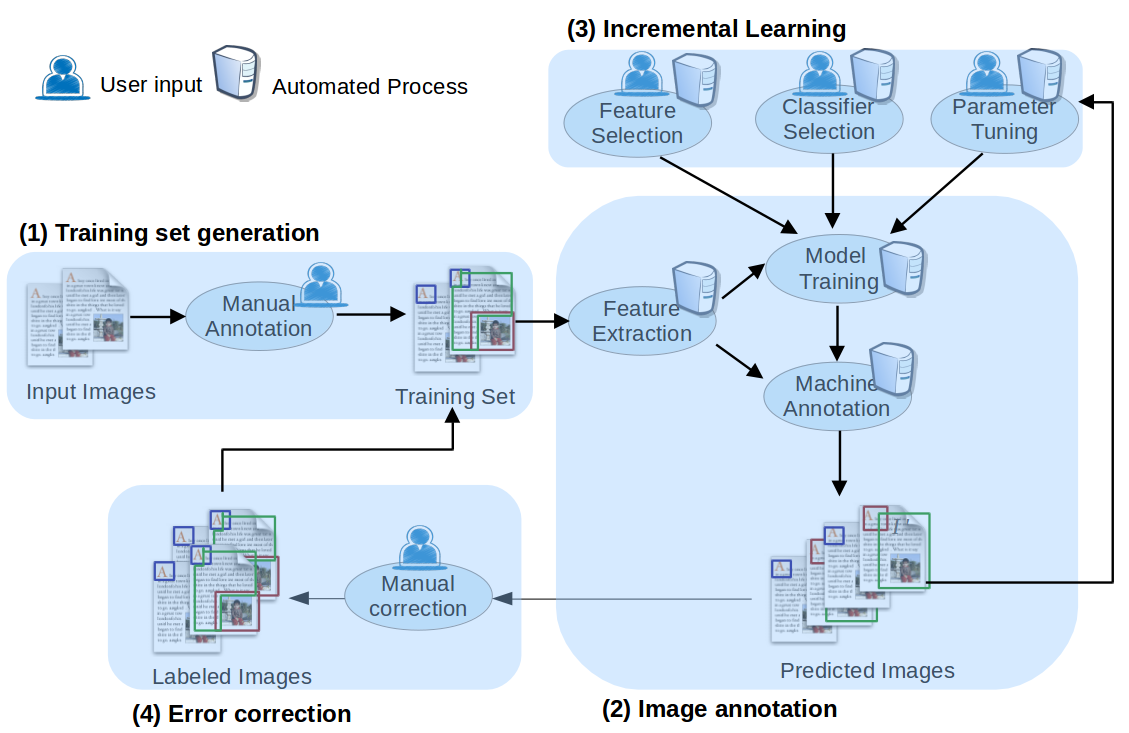
DivaDia is a modular software system with two tiers: the kernel, which actually performs the computation and learning, and the front end (user interface), which handles the interaction with the user. An overview of the processing is given in Fig. 1. In order to start a new labeling process, a user manually annotates several representative page images of a document using DivaDia front end (1).
These images in conjunction with their annotations compile the trainig set for the generation of an initial prediction model, which is computed based on a feature set and an machine learning (ML) algorithm selected by user (2).
Having computed an initial model, the user selects another set of images, which is automatically annotated by ML algorithm based on the model.
The predicted result is presented to the user, who can either manually correct and/or accept the result, or try to improve the model by, e.g., changing the classifier, feature set, or tune parameters; and re-annotate the images (3).
When the user accepts a result, the training set is extended (4) by those newly annotated images, and a refined prediction model is computed.
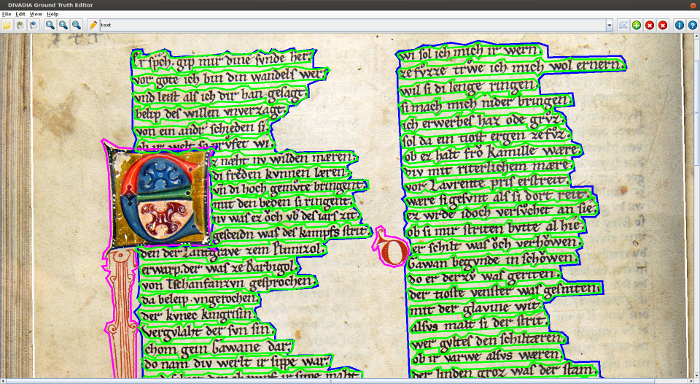
Software DivaDia 1.0
DivaDia 1.0 Java based user interface which aims at providing an environment for creating and manipulating meta data corresponding to regions of interest on the historical document images.
The output is a XML file which is compatible with the PAGE format.
- Ground Truthing tool: divadia1.0.jar
- Source code: DivaHisDocGroundTruth.rar
- User Guide: Divadia-1.0.pdf
-
Sample code: ReadWriteGroundTruthTest.java
(create a new Java project, include divadia1.0.jar as library and run it from ReadWriteGroundTruthTest.java) - Example Image: d-144.png
- Example Ground-truth Image: d-144.gt.png
- Example Ground-truth XML: d-144_kai.chen@unifr.ch.xml
{kind=link}
{kind=link}
Dataset Description
Parzival

Parzival dataset consists of 47 pages by three writers. These pages were taken from a medieval German manuscript from the 13th century that contains the epic poem Parzival by Wolfram von Eschenbach. The image size is 2000 x 3000 pixels. 24 pages are selected as training set; 14 pages are selected as test set; 2 pages are selected as validation set.
Download
- Images: IAM
- Ground truth: ground-truth.rar
Saint Gall

Saint Gall data set consists of 60 manuscript pages from a medieval manuscript written in Latin. It contains the hagiography Vita sancti Galli by Walafrid Strabo. The Abbey Library has a copy of this manuscript within the Cod. Sang. 562. The image size is 1664 x 2496 pixels. 20 pages are selected as training set; 30 pages are selected as test set; 10 pages are selected as validation set.
Download
- Images: IAM
- Ground truth: ground-truth.rar
George Washington

George Washington dataset consists of 20 pages written in English. These pages were taken from letters written by George Washington and his associates in the 18th century. The image size is 2200 x 3400 pixels. 10 pages are selected as training set; 5 pages are selected as test set; 4 pages are selected as validation set.
Download
- Images: IAM
- Ground Truth: ground-truth.rar
Team
Kai Chen, PhD student
Mathias Seuret, PhD student
Hao Wei, PhD student
Dr. Marcus Liwicki
Prof. Dr. Rolf Ingold
Contact
Kai Chen, email: kai.chen@unifr.ch
Marcus Liwicki, email: marcus.liwicki@unifr.ch